- The probably approximately correct (PAC) learning model defines a setting and gives answers to our questions in that setting.
- Leslie Valiant introduced PAC learning in A theory of the learnable [3]. CACM 1984.
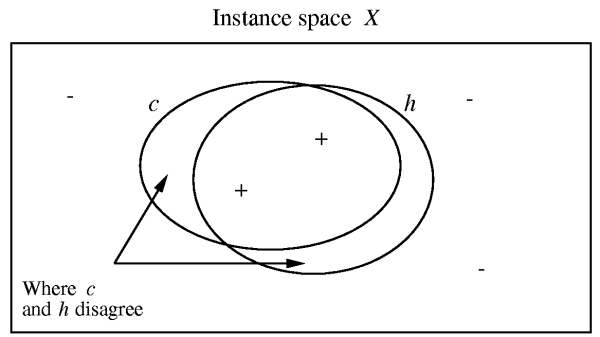
- Roughly, it tells us how many examples (and computation) we will need to see before we can learn a hypothesis is probably H, where H is approximately correct.
- PAC learning results are independent of the learning algorithm used!